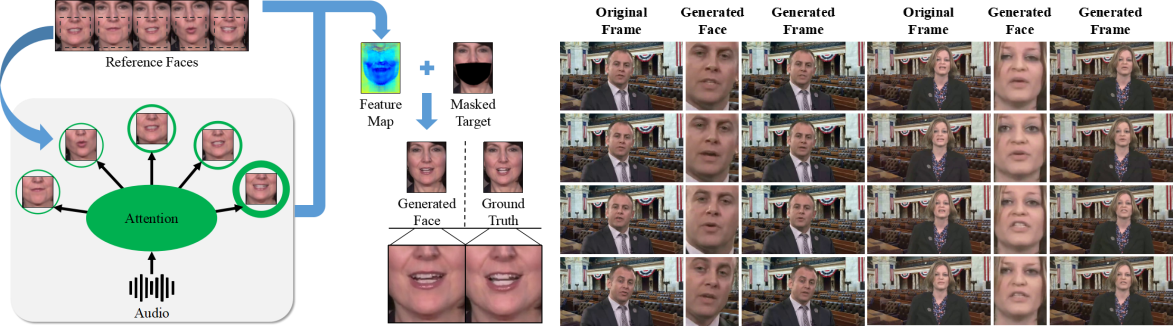
Video dubbing aims to synthesize realistic, lip-synced videos from a reference video and a driving audio signal. Although existing methods can accurately generate mouth shapes driven by audio, they often fail to preserve identity-specific features, largely because they do not effectively capture the nuanced interplay between audio cues and the reference identity's visual attributes. As a result, the generated outputs frequently lack fidelity in reproducing the unique textural and structural details of the reference identity.
To address these limitations, we propose IPTalker, a novel and robust framework for video dubbing that achieves seamless alignment between driving audio and reference identity while ensuring both lip-sync accuracy and high-fidelity identity preservation. At the core of IPTalker is a transformer-based alignment mechanism designed to dynamically capture and model the correspondence between audio features and reference images, thereby enabling precise, identity-aware audio-visual integration.
Building on this alignment, a motion warping strategy further refines the results by spatially deforming reference images to match the target audio-driven configuration. A dedicated refinement process then mitigates occlusion artifacts and enhances the preservation of fine-grained textures, such as mouth details and skin features. Extensive qualitative and quantitative evaluations demonstrate that IPTalker consistently outperforms existing approaches in terms of realism, lip synchronization, and identity retention, establishing a new state of the art for high-quality, identity-consistent video dubbing.
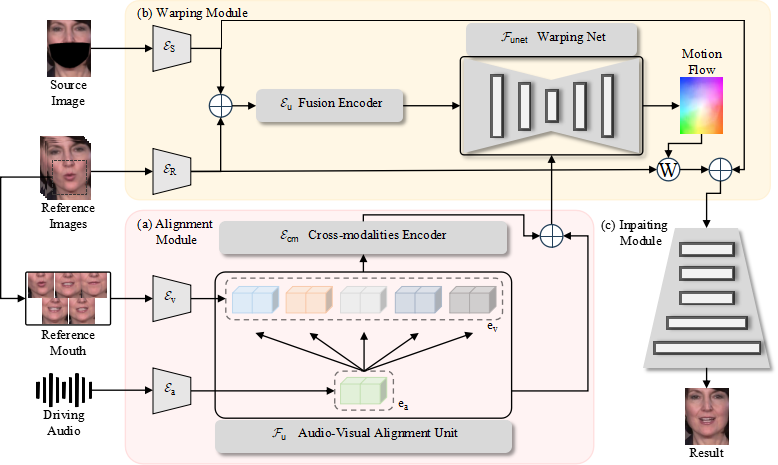
The framework of our method consists of three components: (a) Alignment Module, where reference mouth images and driving audio are input into encoders to extract embeddings. The Audio-Visual Alignment Unit (AVAU) captures the relationships among all embeddings to obtain an identity-audio correspondence embedding. (b) Warping Module, which uses the reference image and the identity-audio correspondence embedding to generate a motion flow that deforms the reference image to match the target configuration dictated by the audio. (c) Inpainting Module, which inpaints the masked source image to produce the final generated image.
@article{liu2025identity,
title={Identity-Preserving Video Dubbing Using Motion Warping},
author={Liu, Runzhen and Lin, Qinjie and Liu, Yunfei and Lin, Lijian and Zhu, Ye and Li, Yu and Xian, Chuhua and Hong, Fa-Ting},
journal={arXiv preprint arXiv:2501.04586},
year={2025}
}